




It all started with Surya posting this on our Teams.

Surya is responsible for our complete backend (platform.integrtr.com) from scratch. I’m not even eligible to rate his AWS/NodeJS/API/Dev Ops skills.
And, Soumyajit chips in. He is our ReactJS/Kubernetes/API guru. He’s singlehandedly responsible for our first consumer app – INTEGRTR.DataFlow (in private beta with customers now – will soon be public).
Above all, both of them are fantastic teachers!

This is asynchronous learning at its best here. OData vs GraphQL has very skewed takes in the start up community. OData is an underdog mostly synonymous with SAP, whilst Facebook incubated GraphQL is a darling and has the zeitgeist of the moment.

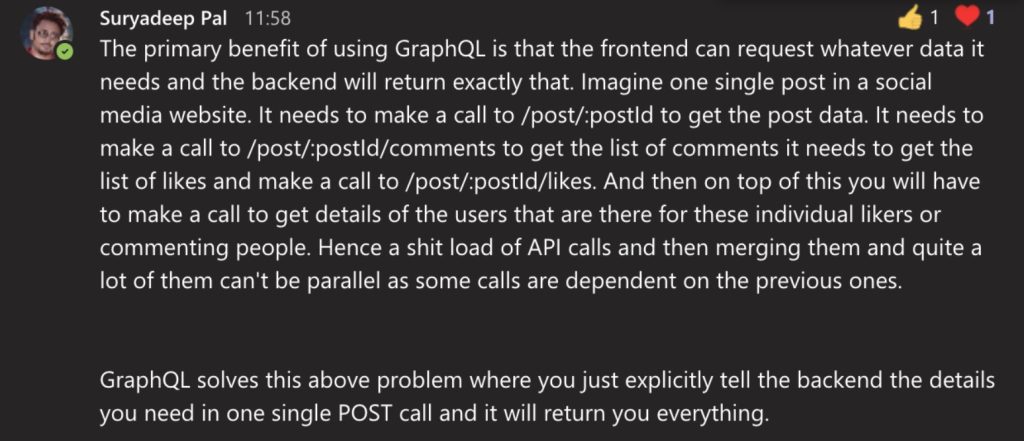
A single end point, deep inserts, mutations are what works for GraphQL

Carpet to hide your ReSTful endpoints is more colloquially known as an API gateway 😉
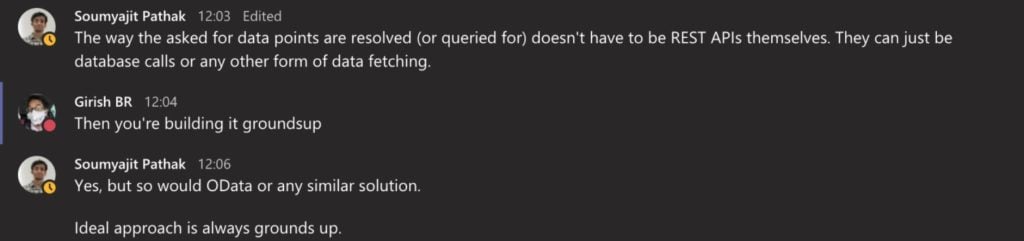
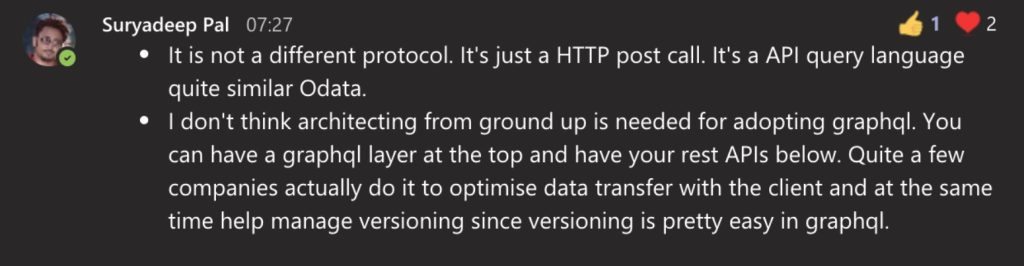
GraphQL’s benefits are obvious if you’re building it grounds up.


GraphQL’s mutations/queries are human readable JSON like declarations. But, that comes at a cost. Steps away from the moment of truth..

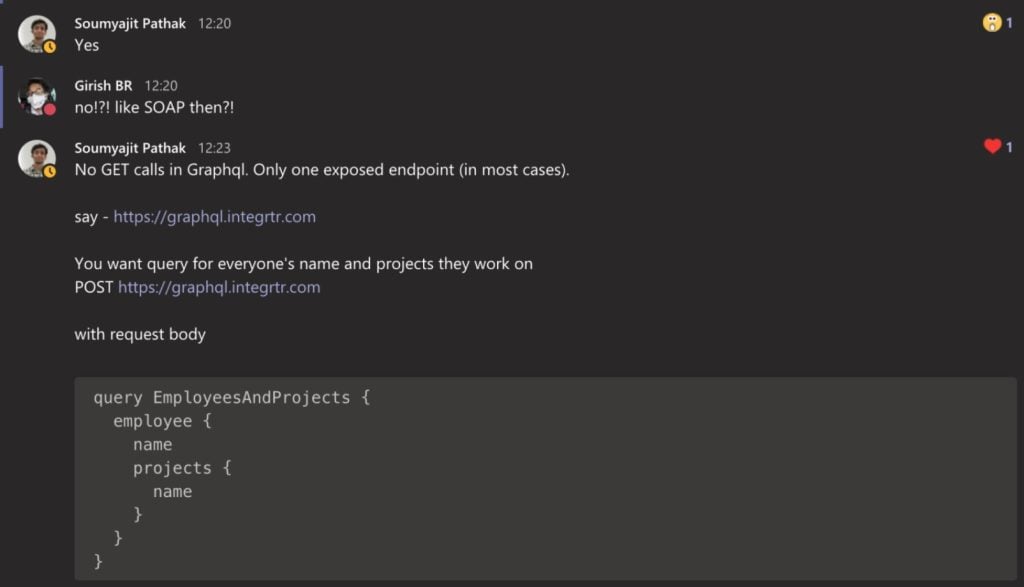
GraphQL is just like SOAP ?! So, it must have its own WSDLish definition? Apparently it does.
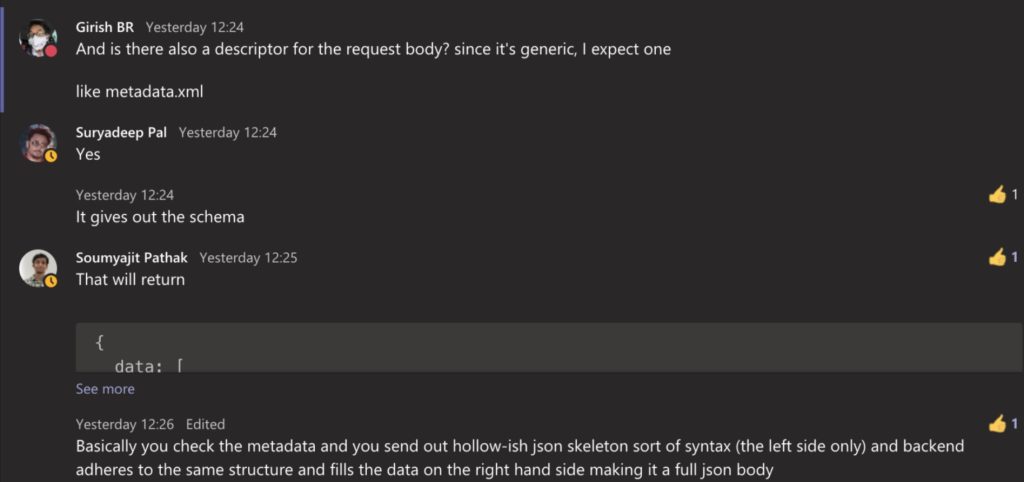
That’s it – settled – this was the moment of truth for me.
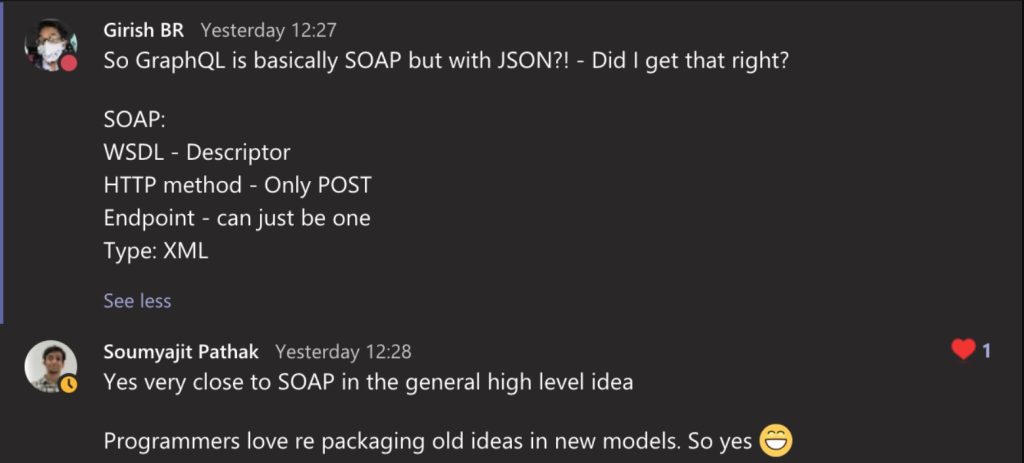
To sum up, this is what I learnt about GraphQL
- It’s a HTTP protocol that’s works a bit to SOAP with only POST and a schema. But it’s a lot more flexible and runs with JSON.
- It’s also like ReST, especially like OData, given its SQL like mutations
- Single end point
- The benefits are palpable and obvious when developed grounds-up. But, one can always start with carpets (gateway) and slowly move closer to data
- Like everything else in the world, it’s usage is purely contextual and is not the one blue pill for the API world.
What an engaging Friday it was? Thank you, Soumyajit & Surya!
Header Image // Picture courtesy: Screengrab from graphql.com






