



In diesem Teil werden wir etwas über Splitter, Groovy-Skript, Message Body, Header und Exchange-Eigenschaften lernen, während wir einen Integrationsfluss für die Verwaltung von Reorder Point (ROP) entwickeln.
Hallo Technologietramper!
Willkommen zum zweiten Teil von Enterprise Integration mit SAP CPI. Im ersten Teil (lesen Sie hier, falls Sie es noch nicht getan haben) hatten wir unser Integrationsszenario festgelegt, den Ansatz in 7 Schritte unterteilt und auch die ersten beiden Schritte der Lösung diskutiert.
- Konfigurieren Sie die Integration so, dass sie jeden Tag ausgeführt wird.
- Erhalten Sie die Liste der Produkte
- Ermitteln Sie für jedes Produkt in der Liste, ob eine Nachbestellung erforderlich ist.
- Wenn das Produkt nachbestellt werden muss, Informationen über den Lieferanten einholen
- Erstellen Sie eine Liste der nachzubestellenden Produkte zusammen mit Lieferanteninformationen
- Liste in csv-Format umwandeln
- Liste per E-Mail an den Manager senden
Außerdem lernten wir die Formen "Start Timer" und "Request Reply" kennen, da wir sie in unserem Integrationsablauf verwendeten.
In diesem Stadium haben wir die Liste der Produkte, für die noch keine Bestellung aufgegeben wurde. Wir müssen die Bestandseinheiten und den Meldebestand für die Produkte prüfen, um festzustellen, ob sie nachbestellt werden müssen. Anstatt zu versuchen, die gesamte Produktliste in einem Durchgang zu bearbeiten, werden wir die Liste in einzelne Produkte aufteilen und dann die Bewertung für ein Produkt nach dem anderen vornehmen.

Dieser Schritt kann in 2 Teile untergliedert werden:
- Wählen Sie ein einzelnes Produkt aus der Liste der erhaltenen Produkte
- Feststellen, ob das Produkt nachbestellt werden muss
Wählen Sie ein einzelnes Produkt aus der Liste der erhaltenen Produkte
(Verwendete technische Begriffe: Splitter)
Um die Liste für die Bewertung in einzelne Produkte aufzuteilen, verwenden wir einen Splitter.
Splitter ist eine Gruppe von Formen, die dazu dienen, eine zusammengesetzte Nachricht in einzelne Nachrichten aufzuteilen. Es gibt verschiedene Arten von Splittern in SAP CPI, wie z. B. Iterating Splitter, General Splitter, EDI Splitter usw. Die am häufigsten verwendeten Splitter sind der allgemeine und der iterative Splitter, die beide dazu dienen, ein allgemeines Dokument in seine einzelnen Elemente aufzuteilen. Der Unterschied zwischen den beiden besteht darin, dass der allgemeine Splitter die umschließenden Tags in die einzelnen Nachrichten einbezieht, während der Iterating Splitter dies nicht tut. Um diesen Unterschied zu verdeutlichen, nehmen wir ein Beispiel.
Angenommen, die Liste der Produkte wird wie folgt gepflegt:
1
Biskuit
2
Tee
3
KaffeeListe der Produkte
Wir können diese Liste entweder mit dem allgemeinen oder dem iterativen Splitter in einzelne Produkte aufteilen. Schauen wir uns die von beiden erhaltenen Ergebnisse an, um den Unterschied besser zu verstehen.
Wenn wir einen allgemeinen Splitter verwenden und nach Produkt aufteilen, erhalten wir das einzelne Produkt als:
1
BiskuitErgebnis: Bei Verwendung von General Splitter
Wie Sie sehen können, ist der umschließende -Tag auch nach der Aufteilung noch vorhanden.
Wenn wir einen iterativen Splitter verwenden und nach Produkt aufteilen, erhalten wir das folgende Ergebnis. Beachten Sie, dass der umschließende -Tag hier fehlt.
1
BiskuitErgebnis: Zur Verwendung des Iterativen Splitters
In einem komplexeren Szenario, in dem die Verschachtelung von Tags tiefer geht, wird der Unterschied viel deutlicher, und Sie müssen entscheiden, welchen Splitter Sie verwenden müssen, je nachdem, ob Sie die umschließenden Tags beibehalten wollen oder nicht.
Nachdem wir nun die Grundlagen von Splittern erörtert haben, wollen wir uns nun mit der Konfiguration des in unserem Szenario zu verwendenden Splitters befassen.
Klicken Sie auf Routing ->Splitter->Allgemeiner Splitter.
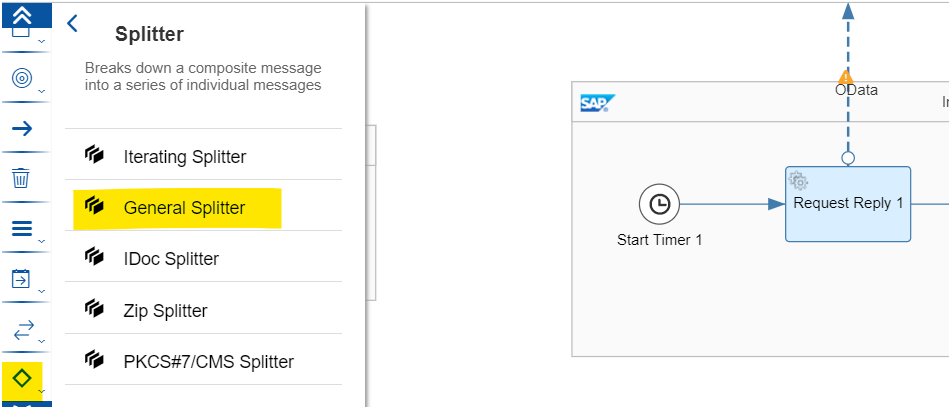
Lassen Sie den Splitter Shape zwischen Request Reply Shape und End Message Shape fallen:
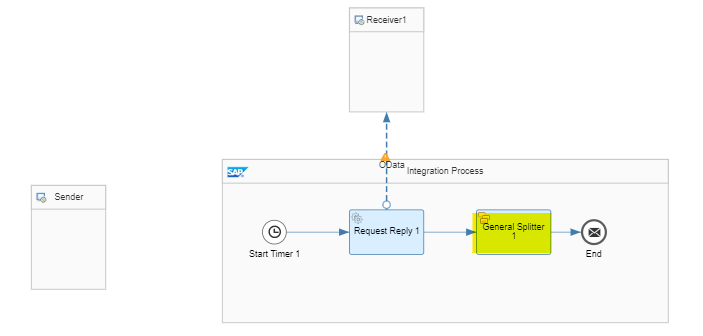
Wir hätten hier auch einen iterativen Splitter verwenden können, aber unser Szenario ist so einfach, dass es keinen großen Unterschied macht. Es folgt die Konfiguration des Splitters:
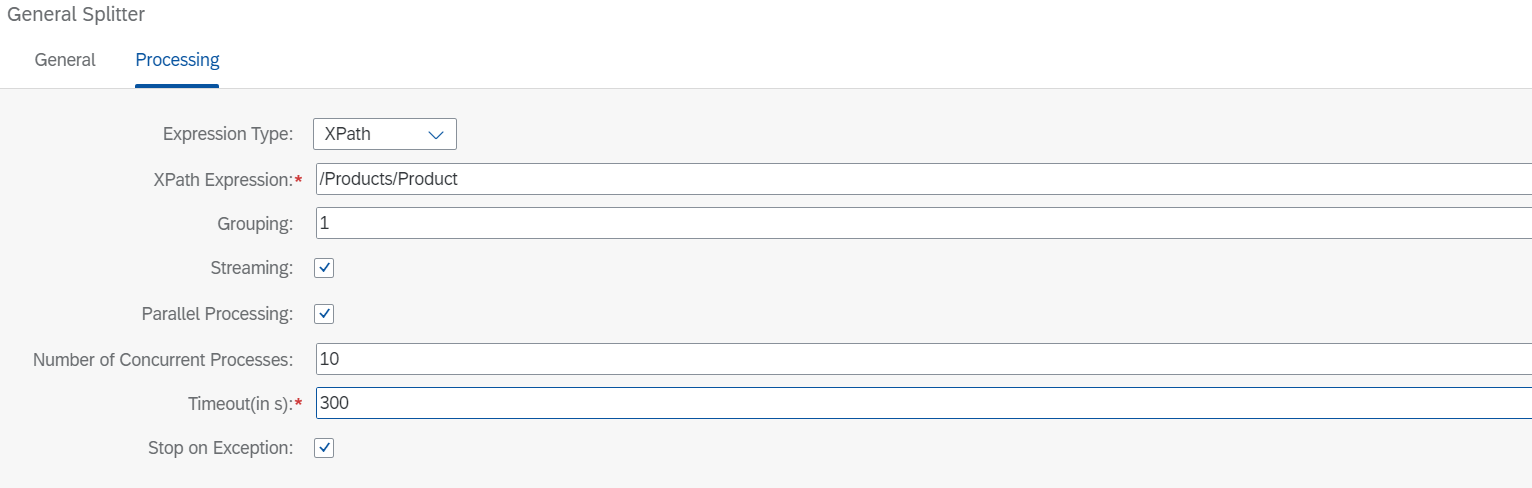
Wir wollen die Liste in einzelne Produkte aufschlüsseln, und da die Liste im XML-Format vorliegt, können wir dazu einen XPath-Ausdruck verwenden. Ausdrucksart zu Xpath. Die Produktdetails sind eingeschlossen in <Product> Tag und alle Produkte sind eingeschlossen in <Products>. Daher ist die XPath-Ausdruck die wir verwenden, ist: /Produkte/Produkt. Außerdem wollen wir uns nur mit den Details eines Produkts auf einmal befassen, daher setzen wir die Gruppierung Parameter auf 1. Wenn wir aktivieren StreamingDer Splitter wartet nicht, bis der gesamte Datensatz geladen ist, bevor er mit der Aufteilung beginnen kann. Sobald die Daten in kleinere Teile aufgeteilt sind, werden diese Teile sequentiell verarbeitet. Wenn zwischen diesen Teilen keine Korrelation besteht, können wir die Parallele Verarbeitung. In unserem Szenario ermöglichen wir eine parallele Verarbeitung, da die Daten für jedes Produkt unabhängig voneinander analysiert werden, um zu prüfen, ob eine Neuordnung erforderlich ist. Wir behalten die Anzahl der gleichzeitigen Prozesse und Zeitüberschreitung Parameter auf den Standardwert gesetzt. Es kann vorkommen, dass bei einem dieser Teile eine Ausnahme auftritt. Durch die Aktivierung von Bei Ausnahme anhaltenWir stellen sicher, dass wir den Rest der Teile nicht verarbeiten.
Nachdem wir nun den Splitter konfiguriert haben, wird die in den vorherigen Schritten erhaltene Produktliste in einzelne Produkte aufgeteilt. Der nächste Schritt besteht darin, zu prüfen, ob das Produkt neu sortiert werden muss. Zu diesem Zweck werden wir ein Groovy-Skript verwenden.
Feststellen, ob das Produkt nachbestellt werden muss
(Verwendete technische Konzepte: Groovy Script)
Die Skripterstellung ist eine der leistungsfähigsten Funktionen von SAP CPI. Wenn keines der vorhandenen Shapes so konfiguriert werden kann, dass es Daten gemäß unseren Anforderungen verarbeitet, können wir ein Skript entwickeln, das unsere Logik implementiert.
In unserem Szenario werden wir ein Groovy-Skript verwenden, um festzustellen, ob ein Produkt nachbestellt werden muss. Um ein Groovy-Skript zu Ihrem Integrationsfluss hinzuzufügen, klicken Sie auf Message Transformers->Script->Groovy Script
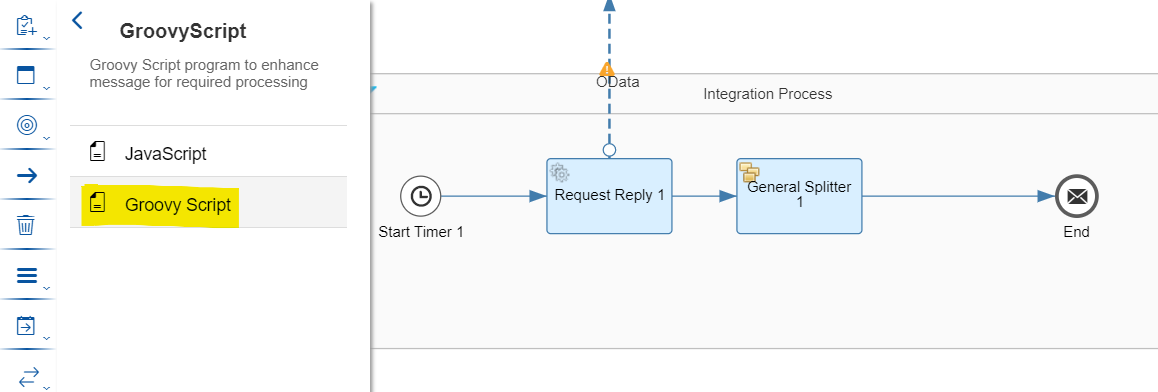
Legen Sie die Form zwischen dem allgemeinen Splitter und der Endnachrichtenform ab.
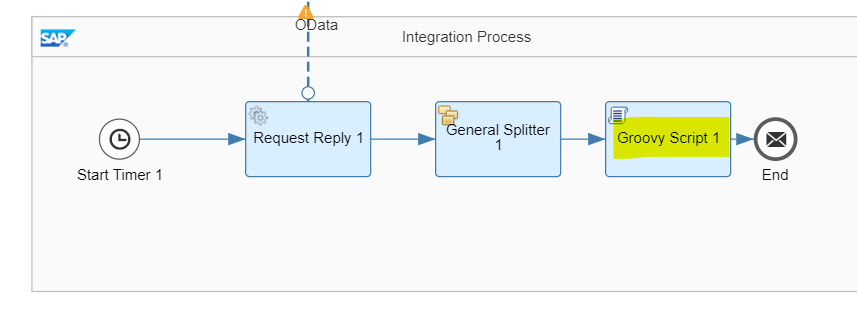
Zu diesem Zeitpunkt haben wir die Form in unseren Integrationsfluss eingefügt, aber es wurde kein Skript zur Groovy-Skript-Form hinzugefügt. Um ein Skript hinzuzufügen, klicken Sie auf die Form und dann auf das + Symbol auf der rechten Seite.
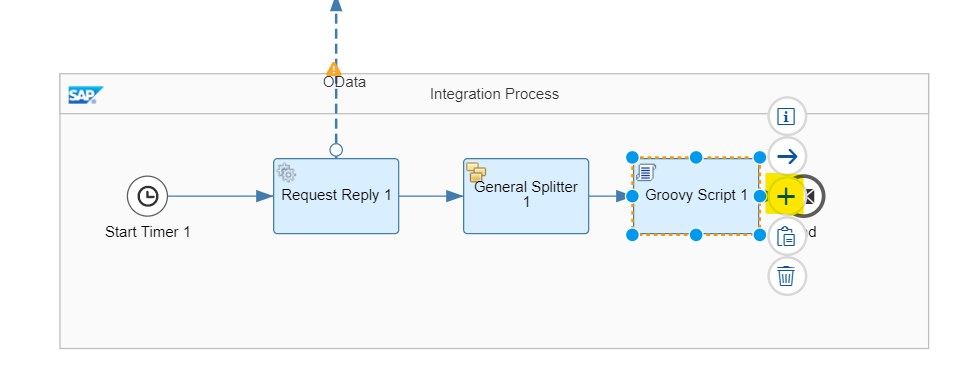
Wenn Sie auf die Schaltfläche + klicken, wird der Form ein neues Skript hinzugefügt:
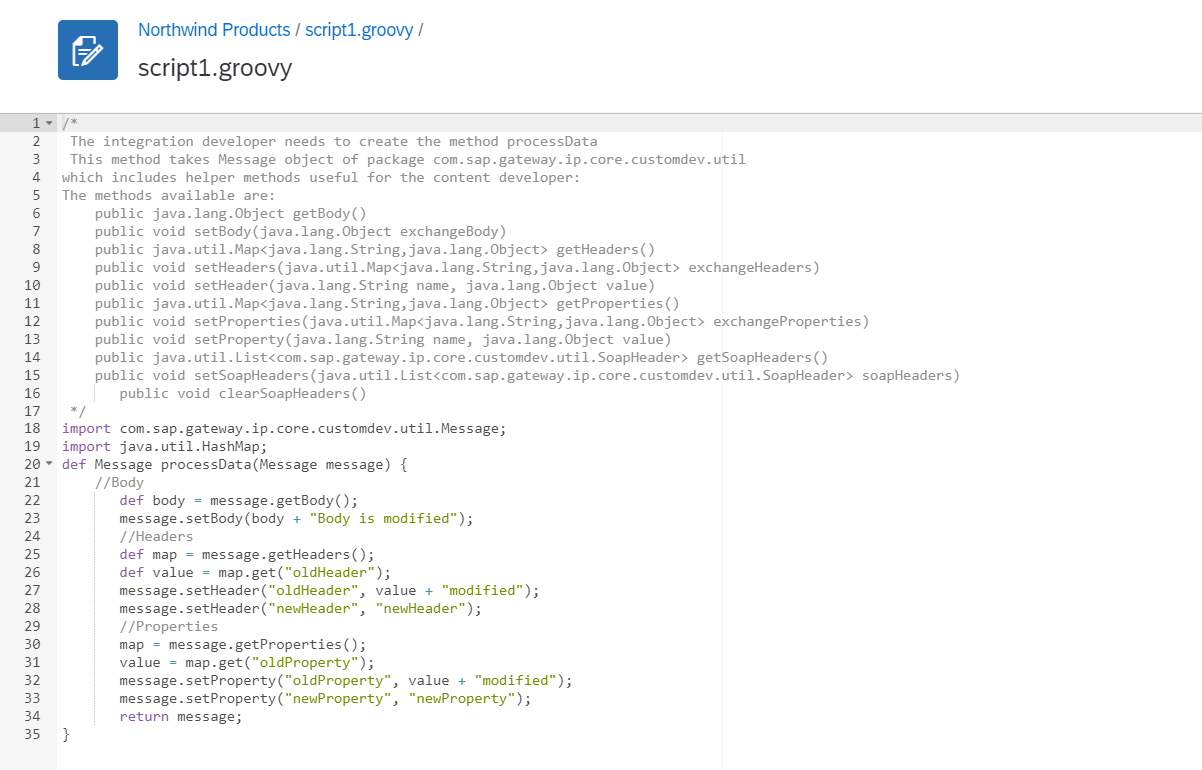
Wie Sie sehen können, enthält dieses Skript eine Methode mit dem Namen "processData", die eine eingehende Nachricht als Argument annimmt und die Nachricht nach der Verarbeitung zurückgibt. Außerdem ist die Methode in 3 Abschnitte unterteilt: Body, Headers und Properties. Jede Nachricht im Integrationsfluss hat eine Körper, Nachrichtenkopfzeilen und Eigenschaften des Nachrichtenaustauschsu.a.. Der Nachrichtentext enthält die Nutzlast. In unserem Szenario enthält er die Produktdaten, die wir in einem früheren Schritt mit Request Reply shape erhalten haben.
Nachrichtenköpfe enthalten in der Regel Metadaten und können zusammen mit den Eigenschaften des Nachrichtenaustauschs zum Speichern von Daten verwendet werden, die nicht Teil des Textes sind, aber für die Verarbeitung benötigt werden. Zum Beispiel können wir nach der Bewertung von Produktdetails einen Parameter in Headers/Properties speichern, der angibt, ob eine Nachbestellung erforderlich ist.
Der Unterschied zwischen den in Header und Property gespeicherten Daten ist der Umfang. Daten werden in Property nur so lange gespeichert, bis sich die Nachricht in der Middleware befindet, und werden nicht an den Empfänger weitergegeben, während in Header gespeicherte Daten an den Empfänger weitergegeben werden.
Nachfolgend finden Sie das Skript, das wir verwenden werden:
import com.sap.gateway.ip.core.customdev.util.Message;
import groovy.util.XmlSlurper ;
import java.util.HashMap;
import groovy.xml.XmlUtil;
def Message processData(Message message) {
def body = message.getBody(java.lang.String) as String;
def reorderLevel;
def unitsInStock;
def product= new XmlSlurper().parseText(body);
reorderLevel=product.Product.ReorderLevel.text().toInteger();
unitsInStock=product.Product.UnitsInStock.text().toInteger();
if(unitsInStock<=reorderLevel){
message.setProperty("needsReorder", "true");
}
sonst{
message.setProperty("needsReorder", "false");
}
return message;
}
In diesem Skript erhalten wir zunächst den Nachrichtentext, der die Produktdaten als String enthält. Beachten Sie, dass die Skriptform nach dem Splitter platziert wurde, so dass der Nachrichtentext Details eines einzelnen Produkts auf einmal enthält und mehrere solcher Segmente parallel verarbeitet werden.
Wir konvertieren den String-Body in einen XML-Knoten mit XML-Schlürfer. XML Slurper wandelt die Zeichenfolge in einen Dokumentenbaum um, der ähnlich wie XPath-Ausdrücke durchlaufen werden kann.
Wir ermitteln den Meldebestand und die Bestandseinheiten der Produkte und vergleichen sie. Wenn der Lagerbestand kleiner oder gleich dem Meldebestand ist, der hier als Schwellenwert dient, setzen wir eine Nachrichtenaustausch-Eigenschaft needsReorder zu wahr. Andernfalls setzen wir ihn auf falsch. Mit diesem Skript können wir also feststellen, ob ein Produkt nachbestellt werden muss oder nicht.
Still, keine Eile! -Portia, Der Kaufmann von Venedig
Da wir uns an die Tugend des langsamen und stetigen Vorgehens erinnern, werden wir hier eine Pause einlegen. In diesem Blogbeitrag haben wir etwas über Splitter gelernt und auch über die Unterschiede zwischen allgemeinen und iterativen Splittern. Außerdem haben wir bei der Entwicklung unseres Integrationsablaufs etwas über Groovy-Skript, Nachrichtenkopfzeilen und Austauscheigenschaften gelernt. Im nächsten Blogbeitrag werden wir unsere Reise der Unternehmensintegration mit SAP CPI fortsetzen. Bis dahin, auf Wiedersehen und viel Spaß beim Lernen!






